
Utah Snow Accumulation Study: Intro and Web Scraping Walkthrough
A run-through of my study on Utah snow data and method of scraping heterogeneous data from online via Python and HTML-Parsing.
Study Introduction
In recent decades, Utah and surrounding states in the U.S. have been experiencing a long-term drought. Lake and reservoir levels have dropped with a shortage of water supply. Communities are scrounging around for methods of efficient water usage to provide for their yards/landscape, other facilities, and living conditions. For the western region of the U.S., one of the primary sources of these issues may be the continuously-changing patterns in snow supply (primarily mountain snow). For communities in this region, winter snowpack is one metric used to determine the quality of the upcoming year when it comes to precipitation levels. However, winter results may also determine the destiny of other aspects of society, such as the success of an economy fractionally built upon agriculture and recreational activities, including golf and skiing.
Due to the importance of understanding these weather patterns in the midst of a long-term drought, I have initiated a study designed to analyze the patterns of snow accumulation over several decades in the state of Utah. The data I have chosen for the analysis is snow level data collected from SNOTEL sites located across the state of Utah. The observations were collected by the USDA and included in their Air & Water Database. The following section discusses my methods of extracting the data online and cleaning it in preparation for exploratory data analysis (EDA).
Collecting and Cleaning the Data
Web Scraping Walkthrough
We live in a world with mountains of information released to the internet daily, and, therefore, plenty of resources to learn from and use for our studies. However, with this infinite collection of news stories, studies, words, and numbers at our fingertips, it can be difficult to target the desired data needed to analyze a specific issue—in this case, Utah snow levels over time. It would certainly be useful to retrieve optimal data for this study, and web scraping is certainly a good way to retrieve it.
Web scraping takes shape in various ways and through different tools—in this case, I am going to use the Selenium package in Python as I parse through USDA’s site and extract text file data for cleaning and EDA. There are, of course, other packages in Python, such as BeautifulSoup4, or even other methods of scraping, such as APIs, you can use to attain data from online sources. If you would like to learn more about these other options for web scraping, I suggest you look into Beautiful Soup Documentation and API Sources to get started.
The following is the main page I am scraping from:
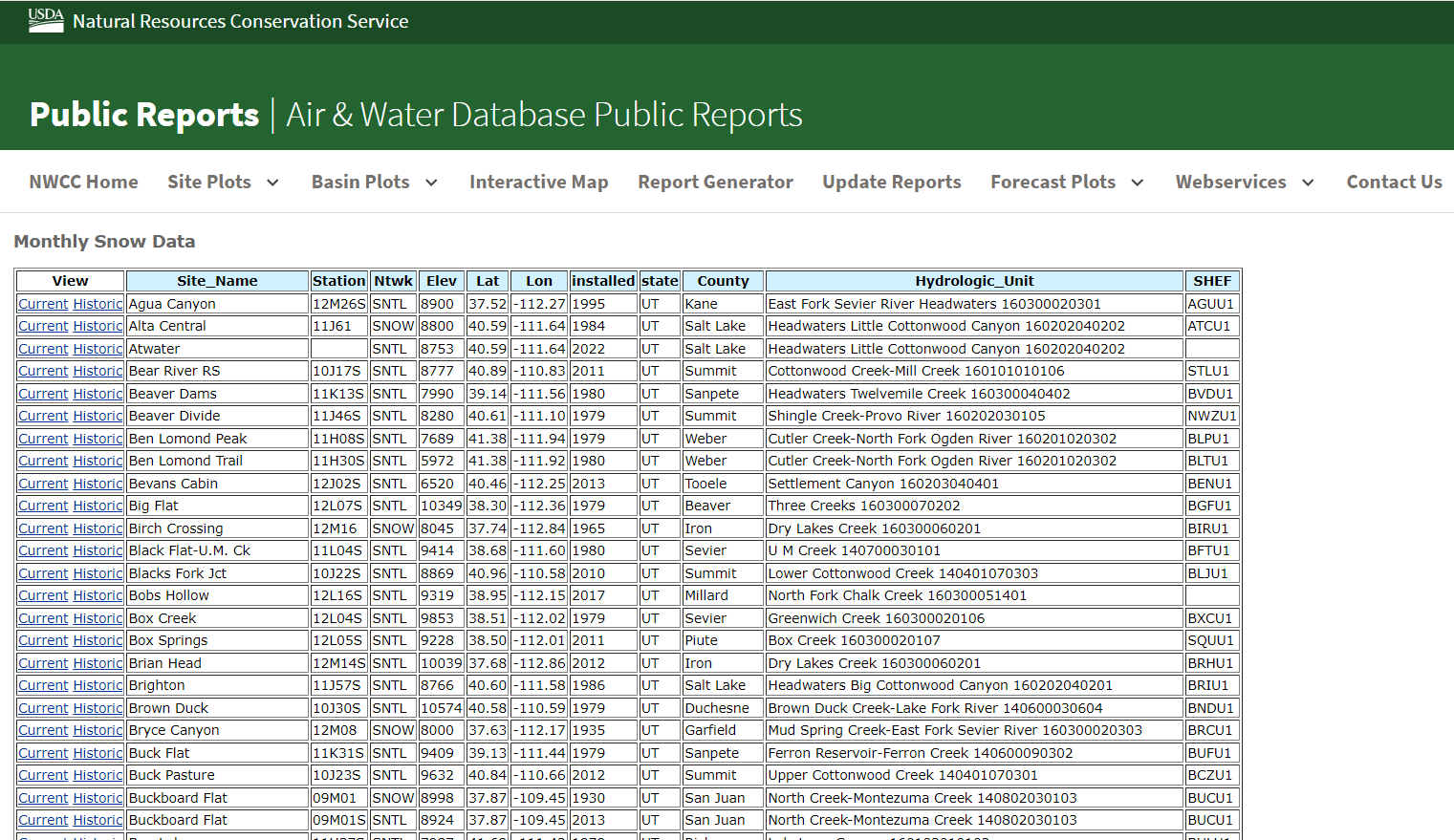
Because the table on this page is an html table, I was able to simply read it into my Python environment:
---
home_table = pd.read_html('https://wcc.sc.egov.usda.gov/nwcc/snow-course-sites.jsp?state=UT')
home_table = home_table[0]
---
However, this data only includes information about each site name, location, elevation, etc. To obtain the snow levels over the years, I needed to access the text files found through the “Historic” links as can be seen in the “View” column.
I use the Selenium package in this step due to its efficiency in accessing links via webdriver and scraping the contents into a Python environment. I proceed to parse through the page’s HTML structure and locate the respective tag names for the “Historic” links. I then proceed to use a for loop to iterate through each link and save text data comparable to the following:
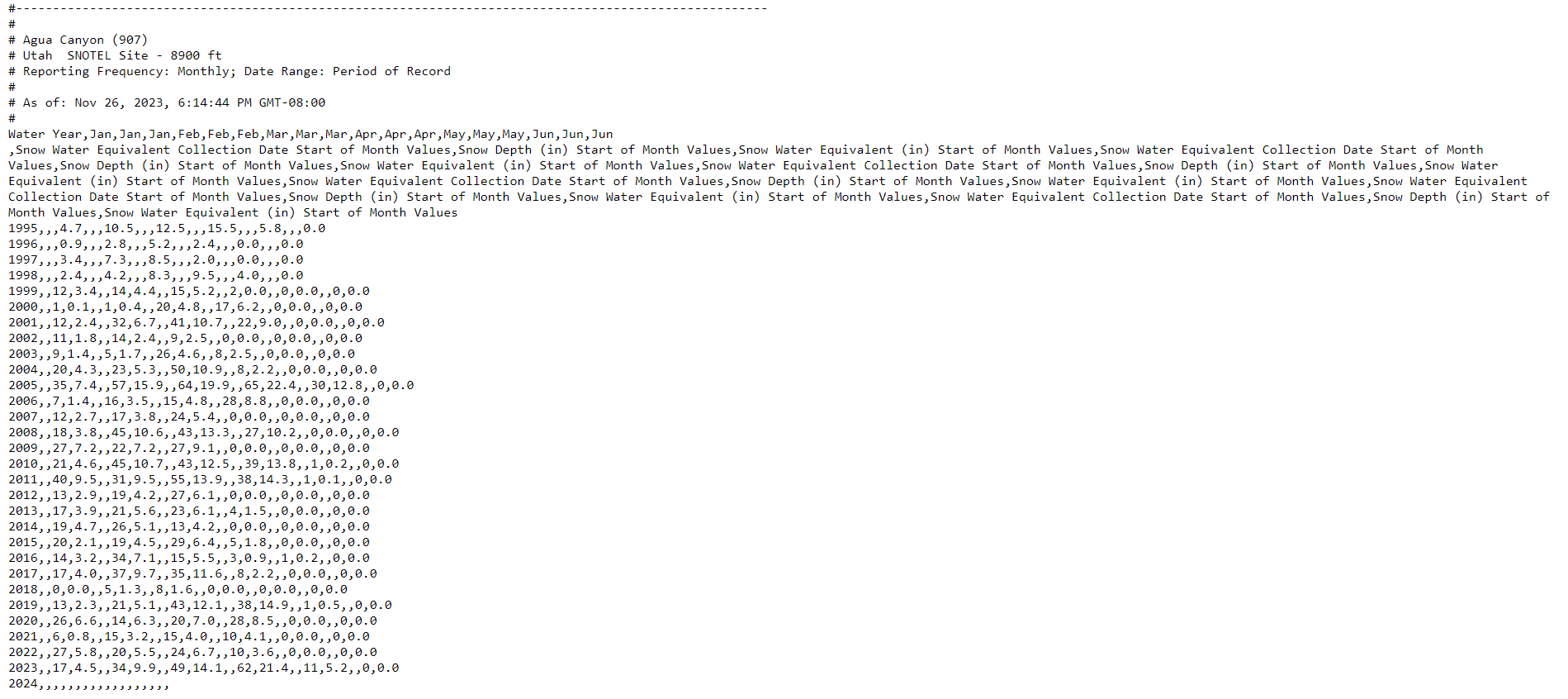
There’s a lot more to these text files, but this portion is where the desired data is located.
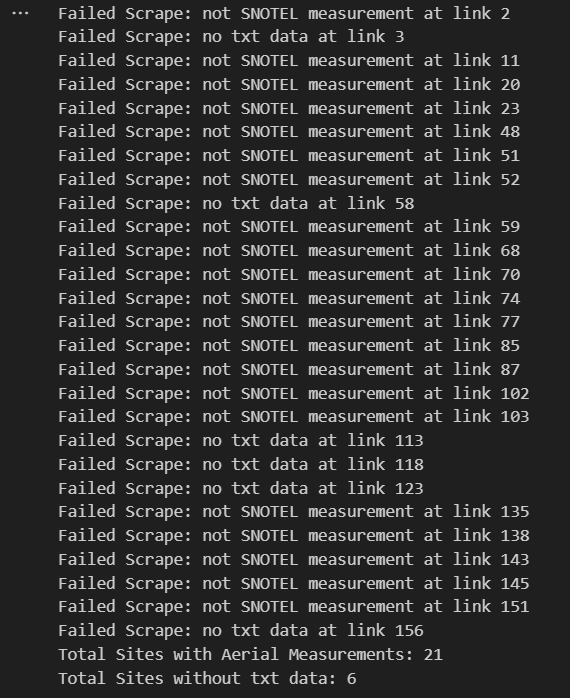
I proceed to save the contents from each link as text. However, some sites only contain manually-measured snow levels, rather than SNOTEL measurements. Some other links lead to empty pages. In my for loop, I ignore these files and attach the ones that contain the appropriate data, and split the text to only include what I need:
(portion of the for loop)
---
r = requests.get(links[site])
r_txt = r.text
if 'Water Year' in r.text:
if 'AERIAL' in r.text:
print('Failed Scrape: not SNOTEL measurement at link ' + str(site + 1))
aerial_count += 1
else:
r_txt = re.split(r'(Water Year)', r_txt)
r_txt = r_txt[1] + r_txt[2]
---
While running my for loop, I output the following to keep track of the links that do not work:
As for the rest of the for loop, I convert the newly-imported text into rows, and convert the text into a dataframe with snow month and water equivalent (WE) month columns accordingly:
---
# Split up string into rows using \n string
r_txt_rows = r_txt_clean.split('\n')
# Convert rows of text into a Dataframe:
r_txt_df = pd.DataFrame([line.split(',') for line in r_txt_rows])
#####Remove empty cols in Dataframe:
r_clean_df = r_txt_df.drop(r_txt_df.columns[[1, 4, 7, 10, 13, 16]], axis=1)
#####Rename First row cells
r_clean_df.at[0, 3] = 'Jan (WE)'
r_clean_df.at[0, 6] = 'Feb (WE)'
r_clean_df.at[0, 9] = 'Mar (WE)'
r_clean_df.at[0, 12] = 'Apr (WE)'
r_clean_df.at[0, 15] = 'May (WE)'
r_clean_df.at[0, 18] = 'Jun (WE)'
##### Set first row to column index
r_clean_df.columns = r_clean_df.iloc[0]
r_clean_df = r_clean_df.iloc[1:].reset_index(drop=True)
##### Add Site_Name to r_clean_df
r_clean_df['Site_Name'] = home_df['Site_Name'][site]
snow_main = pd.concat([snow_main, r_clean_df], ignore_index=True)
---
Luckily, the SNOTEL text files all follow the same format for their recorded observations. As can be seen above, I concatenate each newly-created dataframe into a main dataframe titled “snow_main”.
I merge snow_main to home_table in the data cleaning process.
Cleaning the Data
The first step I took in cleaning my scraped datasets in preparation for EDA involved dropping null values from the snow and WE measurement columns. I found some of the online text files to be inconsistently empty in their snow-level observations, and determined it would be best to only include rows (by year) with values for at least half of its columns—this is because some text files only included snow observations with their associated WE observations being NULL. Thus, after dropping rows with a majority of NULL observations, my next step was to fill in the missing WE levels.
To fill in the remaining NULL values in the WE columns, I calculated a “Snow / WE Coefficient” to determine a broad relationship between Utah snow and its water equivalent levels. I did so by taking all rows containing values for each of its respective columns (both snow and WE levels for each month) and averaging the fraction of snowfall/WE for each month, January through April:
---
######### Snow / WE Coefficient #####################################
# Drop all rows with NAs
snowfall_vals = snow_main.dropna().reset_index(drop=True)
# Drop all rows with 0 to avoid nan vals and averages weighted to 0
snowfall_vals = snowfall_vals[~(snowfall_vals == 0).any(axis=1)]
snowfall_vals= snowfall_vals.reset_index(drop=True)
# Snow to WE coefficient (average of ~400 vals of snowfall/WE)
snow_we_coeff = np.mean([(snowfall_vals['Jan'] / snowfall_vals['Jan (WE)']), (snowfall_vals['Feb'] / snowfall_vals['Feb (WE)']), (snowfall_vals['Mar'] / snowfall_vals['Mar (WE)']),
(snowfall_vals['Apr'] / snowfall_vals['Apr (WE)']), (snowfall_vals['May'] / snowfall_vals['May (WE)']), (snowfall_vals['Jun'] / snowfall_vals['Jun (WE)'])])
---
Of course, this process assumes that the ratio of snow to WE is comparable across all sites in the state of Utah. Luckily, results from my EDA support this assumption (see results in next post). I proceed to take the mean of these monthly ratios to calculate an estimate for the WE of observations according to their observed snow level.
Having cleared out my fully-null observations while filling in other partially-null ones (with missing WE values), I proceed to merge the snow level dataframe with home_df, in order to combine SNOTEL sites with their associated observations over the years:
---
# Merger:
site_snow_main = pd.merge(home_df, snow_main, on='Site_Name', how='inner')
---
Ethics in the Study
The main ethical question in this study has to do with on ongoing debate, which is the ethics of web scraping. Is it ethical to freely-access data available on the internet for a study?
One of my answers to this question is that it depends on what sources you are using. Similarly with citing a source for an academic paper, scraping data from on online source for a study must be a careful process, and you must take caution when deciding on what source to scrape from. Some sites are more reliable than others, and scraping data from a controversial source may prove problematic in determining the veracity of your findings.
My other answer is that the debate for and against web scraping is ongoing, but there are certainly some helpful sources to look to when determining if it is ethical or not. Some good sources to look to are academic papers, such as Scraping the Web for Public Health Gains: Ethical Considerations….
Conclusion
I find web scraping to be incredibly useful, especially with the internet and its resources available to us. I will continue discussing my analysis on snow accumulation in Utah over time—particularly my EDA and results—in my next post (see links).